알고리즘
퀵정렬(Quick Sort) 설명
ris
2025. 5. 26. 23:33
최근 알고리즘 문제를 다시 풀어보며 까먹었던 정렬 알고리즘들에 대해서 복습하는 시간을 가졌었다.
그중 가장 애용하고 있는 정렬인 퀵정렬에 대해서 설명해보고자 한다.
퀵정렬 작동 방식
퀵정렬의 작동 방식은 의외로 간단하다.
어찌보면 선택 정렬과도 유사하다. (선택 정렬은 추후에 다룰 예정이다.)
하지만 퀵정렬은 재귀적인 방식을 채택한다.
그리고 퀵정렬은 크게 3가지 단계를 거치는데
- 분할(Divide) : 정렬할 배열을 2~1개의 칸으로 나눈다. 정렬할 구역은 2개로 이루어진 칸이다.
- 정복(Conquer) : 나눠진 배열을 부분 배열이라 말하며, 부분 배열을 정렬한다.
- 결합(Combine) : 정렬된 배열을 다시 하나의 배열에 결합한다.
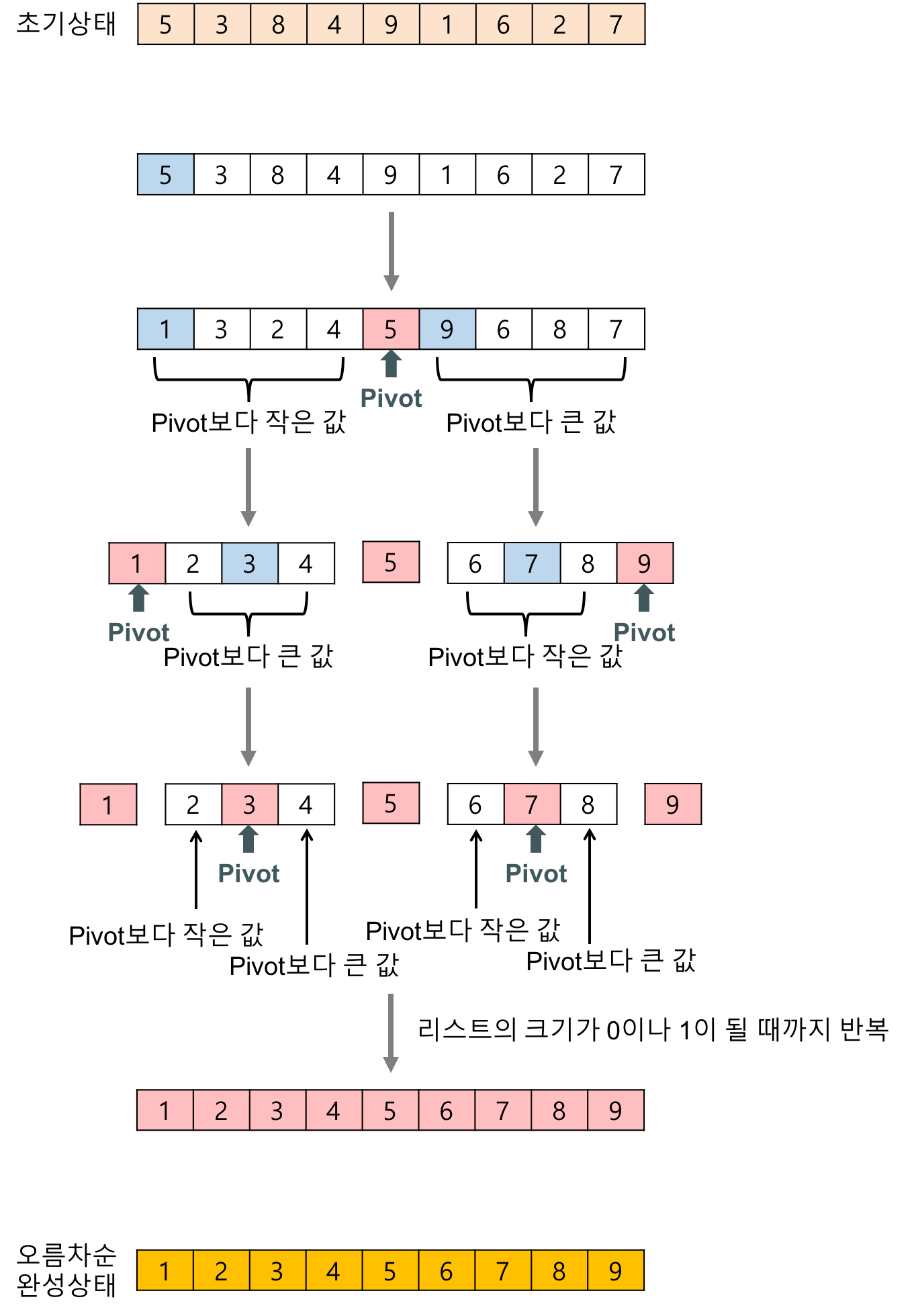
그리고 가끔 알고리즘 문제에서 순서에 민감한 문제들이 있다.
이런 문제들에서는 퀵정렬을 사용하는 것을 다시 고민해보는 것이 좋다.
왜냐하면 퀵정렬은 불안정 정렬이기 때문이다.
저 불안정 정렬이란 말이 사실 크게 와닫지는 않는다.
그러니 예시를 보여주겠다.
#include <stdio.h>
#define N 5
void swap(int *a, int *b) {
int temp = *a;
*a = *b;
*b = temp;
}
void q_sort(int *list, int s, int e) {
if(s >= e) return;
int pivot = s, i = s + 1, j = e;
while(i <= j) {
while(i <= j && list[i] <= list[pivot]) i++;
while(i <= j && list[j] > list[pivot]) j--;
if(i < j) swap(&list[i], &list[j]);
}
swap(&list[j], &list[pivot]);
q_sort(list, s, j - 1);
q_sort(list, j + 1, e);
}
int main() {
int list[N] = {5, 3, 4, 1, 2};
q_sort(list, 0, N - 1);
for(int i = 0; i < N; i++) {
printf("%d ", list[i]);
}
return 0;
}

위 코드는 개인적으로 가장 많이 쓰는 퀵정렬 형태이다. 다른 형태도 많지만 3단계를 한번에 처리하는 것이 보기 편해서 이렇게 쓴다.
사실 나도 퀵정렬을 쓰면서 불안정 정렬이란 것을 느끼지 못했었다.
그러나 이건 1차원 배열에 한정한 얘기이고, 만일 2차원 배열로 넘어가 각 원소의 값과 연결된 다른 값들도 중요해진다면 얘기가 달라진다.
#include <stdio.h>
#define N 4
typedef struct {
int score;
char name[10];
} Student;
void swap(Student *a, Student *b) {
Student temp = *a;
*a = *b;
*b = temp;
}
void q_sort(Student *list, int s, int e) {
if(s >= e) return;
int pivot = s, i = s + 1, j = e;
while(i <= j) {
while(i <= j && list[i].score <= list[pivot].score) i++;
while(i <= j && list[j].score > list[pivot].score) j--;
if(i < j) swap(&list[i], &list[j]);
}
swap(&list[j], &list[pivot]);
q_sort(list, s, j - 1);
q_sort(list, j + 1, e);
}
int main() {
Student list[] = {
{90, "홍길동"},
{70, "오철수"},
{90, "한나빛"},
{60, "김영희"}
};
q_sort(list, 0, N - 1);
for(int i = 0; i < N; i++) {
printf("%d %s\n", list[i].score, list[i].name);
}
return 0;
}
동일한 점수의 홍길동과 한나빛의 순서가 바뀌었다는 것을 알 수 있다.
이것이 불안정 정렬의 예시이다.
동일한 점수이지만 본래 순서를 지키는 것을 안정 정렬이라고 말한다.
이제 본격적으로 코드를 해설하려고 한다.
개념만 알고서는 구현하기 어렵기 때문이다.
세세한 부분에서 집중해야 한다.
해설은 주석을 통해 진행하겠다.
#include <stdio.h>
#define N 5
// 두 값의 위치를 교환하는 함수
void swap(int *a, int *b) {
int temp = *a;
*a = *b;
*b = temp;
}
void q_sort(int *list, int s, int e) {
// 분할된 구간이 2개 미만일 때 정렬 완료
if(s >= e) return;
// pivot을 배열의 첫 번째 원소로 설정
int pivot = s;
// i: 왼쪽에서 오른쪽으로 이동하며 pivot보다 큰 값을 찾는 포인터
int i = s + 1;
// j: 오른쪽에서 왼쪽으로 이동하며 pivot보다 작거나 같은 값을 찾는 포인터
int j = e;
/*
분할 과정:
- left 영역: pivot보다 작거나 같은 값들
- right 영역: pivot보다 큰 값들
- i와 j가 교차될 때까지 반복하여 잘못된 위치의 값들을 교환
*/
// i와 j가 교차될 때까지 반복 (i <= j 조건)
// 교차되어야 pivot의 올바른 위치를 찾을 수 있음
while(i <= j) {
// 왼쪽에서 오른쪽으로 이동하며 pivot보다 큰 값을 찾음
while(i <= j && list[i] <= list[pivot]) i++;
// 오른쪽에서 왼쪽으로 이동하며 pivot보다 작거나 같은 값을 찾음
while(i <= j && list[j] > list[pivot]) j--;
// 아직 i와 j가 교차하지 않았다면 잘못된 위치의 값들을 교환 (같은 위치에서 교환하는 것 방지지)
if(i < j) swap(&list[i], &list[j]);
}
// pivot을 올바른 위치(j)에 배치
// j 위치는 pivot보다 작거나 같은 값들의 마지막 위치
swap(&list[j], &list[pivot]);
// 분할된 왼쪽 부분 (pivot보다 작거나 같은 값들) 재귀 정렬
q_sort(list, s, j - 1);
// 분할된 오른쪽 부분 (pivot보다 큰 값들) 재귀 정렬
q_sort(list, j + 1, e);
}
int main() {
int list[N] = {5, 3, 4, 1, 2};
q_sort(list, 0, N - 1);
for(int i = 0; i < N; i++) {
printf("%d ", list[i]);
}
return 0;
}